

Introduction
In today's world, organizations continuously face the challenge of processing information distributed across multiple systems. Traditional relational databases are severely limited in handling complex relationships and numerous tables, leading to low performance when working with data where the structure and shape of data relationships are crucial.
Our client requested the creation of a Customer 360 platform that would consolidate all information about their users. However, it turned out that the client's business data was scattered across different systems—a CRM platform, outdated SQL databases, multiple generations of Google Workspace accounts with several thousand spreadsheets, plus weekly CSV exports from an IoT platform requiring manual transformation before analysis. Due to this, it was almost impossible to analyze the data efficiently, as controlling such a large volume of fragmented data was extremely difficult. In other words, we start running out of engineers and cloud costs.
Implementing our solution through graph databases was the most suitable approach for our case - we successfully applied graph databases for our recommender system within an on-premise client’s infrastructure. This gave us valuable experience and allowed us to see the power of such models in data processing. Obviously, before the implementation of this part of system, we tested the potential open-source ( or withan adequate price ) solutions to compare their performance.
Based on the client's data, we formed the following requirements for the database:
- Fast graph lookup (< 20 ms per query)
- Comparatively low pricing or priceless
- Comprehensive documentation for troubleshooting
Our fault - we tested on key-value queries instead of full graph search, but the life showed that they are correlated.
Our market research led us to three candidates. We evaluate based on three key parameters: support, popularity, and pricing. The explanation of how we rank will be explained below, and our notes state the following:
The versions we tested:
- Memgraph v3.1.1
- Neo4j v5.26.4
- NebulaGraph v3.6.0
| Support | Popularity | Pricing | |
| Neo4j | 10 | 9.2 | 6 |
| Memgraph | 3.07 | 0.2 | 7 |
| Nebula | 5.38 | 0.2 | 8 |
Despite the low user engagement in Google Trends for Memgraph and Nebula Graph, their repository activity is high, which persuaded us to consider these projects. Additionally, from a cost perspective, these solutions are rather attractive.

When evaluating the popularity of databases, Google Trends analytics was used. It should be noted that for Nebula Graph, the majority of search queries come from China — its popularity may be significantly higher in local Chinese search engines than reflected in global Google Trends data.

Regarding Memgraph—this is a niche project focused on specific tasks and high-performance in-memory processing. Due to its narrow specialization, its audience is smaller compared to more universal solutions like Neo4j, which explains its low popularity in general search trends.
Testing Methodology
To ensure a fair comparison, we established identical conditions for all databases. For each test, we generated a uniform social graph dataset containing 50,000 nodes and roughly 100,000 relationships. Write queries involved creating a single link between two nodes; if these nodes didn't already exist, they were created as part of the query.
Example of such a query:
| Cypher: MERGE (a:Person }) MERGE (b:Person }) MERGE (a)-[:KNOWS{prop_str}]->(b); NGQL: INSERT VERTEX IF NOT EXISTS Person() VALUES "{source}":(), "{target}":(); |
Read queries, on the other hand, involved requesting a random node from the total of 50,000 nodes.
Example of such a query:
Cypher: OPTIONAL MATCH (x:Person }) RETURN x |
We utilized 60 (sixty) workers for executing write queries and 4 (four) workers for read queries across all database configurations.
Measured Characteristics:
- How quickly the database loads data.
- The time required for reading and writing information (along with the latency and throughput).
- The utilisation of server resources includes CPU, memory, and I/O disk consumption.
- Compliance with the ACID (atomicity, consistency, isolation, durability) standard.
The test environment was based on containers with Containerd under the hood.
The conditions for all test subjects (DB types and configurations) were made as uniform as possible:
- The entire environment was deployed using standard ContainerD containers.
- Each database was deployed in a separate container (set of containers).
- The hardware setup of the test stand was the following: CPU Intel Xeon Gold 6142, 64 cores, 125 GiB RAM - limited to 12 GB to do the fair testing with in-memory Graph databases, and LVM of three 3rd-gen NVME of 4TB disk (VO003840KWUEC).
- A separate instance of each database was launched on the same test server.
However, Nebula Graph's inherently clustered architecture posed limitations on test fairness. Therefore, for Nebula Graph, we launched a separate container instance on the server for each service role (metadata storage, graph engine, and data storage).
Now, let's move on to the testing results for each of the database configurations.
Neo4j
Test 1: Neo4j with Basic (Default) configuration with no memory

Both write and read queries show good performance, typically Neo4j has huge skew to the right - which will be seen for all Neo4j tests. This pattern may lead to problems in systems that are sensitive to the stable performance of read and write operations.

CPU usage correlates with disk utilization, indicating that IO operations are the main consumers of processor resources.
Test 2: Neo4j with G1GC

In this and subsequent tests, we decided to set the minimum and maximum memory allocation limit to 12 GB, allowing the JVM to manage resource allocation on its own with a minimum amount of system calls.
The performance is slightly lower, approximately by 0.3 ms for writes and 1 ms for reads.

Aside from memory usage itself, adjusting the minimum and maximum memory had no other impact on the test stand.
Test 3: Neo4j with ZGC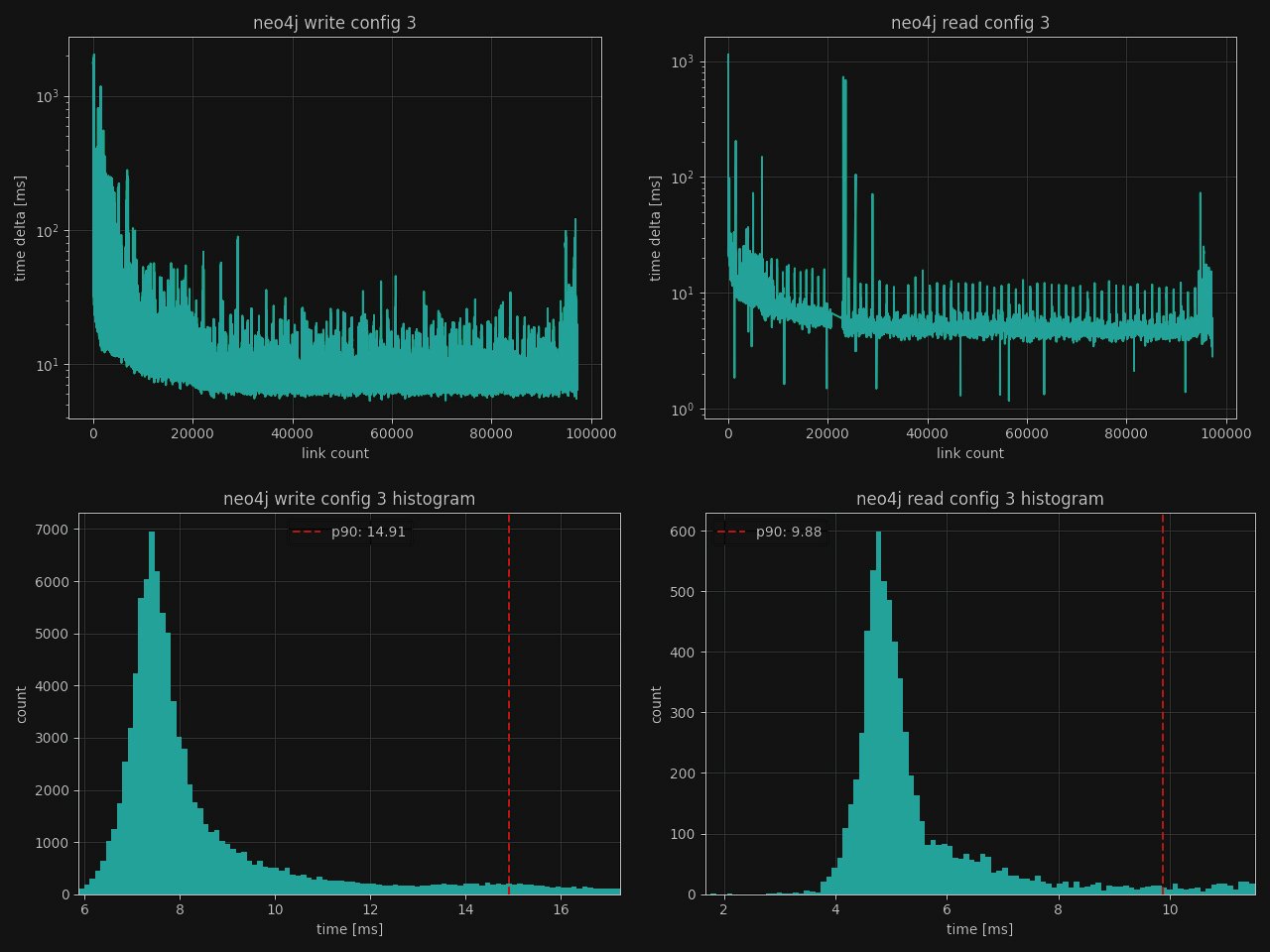
We've switched this configuration to use the Z Garbage Collector (ZGC) to evaluate its impact on database performance. The ZGC is a modern memory garbage collector that is specifically designed for low-latency collection even for heaps of size up to .16 TB

The overall CPU consumption has dropped approximately by 5%, and the amount of used memory has slightly decreased by 2 [GiB] which makes this garbage collector a preferable choice.
Test 4: Neo4j with ParallelGC

In the current configuration, we switched to the parallel garbage collector, which did not significantly impact the test results – the read speed remained the same and within specified limits, and CPU load has not changed.

Test 5: Neo4j with Advanced ZGC Configuration

Our final test utilized a highly customized configuration that performed normally on the test data. This configuration was explicitly designed to pre-allocate all available resources and minimize userspace/kernelspace transitions. This approach resulted in a slight increase in overall CPU usage, along with increased RAM consumption, but caused no other significant system changes.

Memgraph
Test 6: Memgraph in Transactional mode

Our tests showed promising results with the standard Memgraph configuration, primarily thanks to its architecture, which stores all accessed data in RAM. It is curious that in comparison to neo4j, it takes quite a lot of time to write to the database; however, read performance is exceptionally fast (5-6 times faster than for Neo4j tests) and also offers ACID guarantees.

Memgraph's CPU load is half that of Neo4j, making it a strong competitor. The disk utilization plot reveals periodic writes during script execution; these are snapshots designed to prevent data loss and allow for restoration procedures.
Test 7: Memgraph in Analytical mode

This configuration ran with analytical processing enabled, a mode that significantly boosts query speed by disabling ACID compliance. While this makes it unsuitable for operations demanding high data integrity (like financial transactions) due to increased risks of data loss or corruption, it's highly effective for business intelligence analytics. Such tasks primarily involve reading large datasets with minimal data modification or insertion. This mode is also useful for backup and restore operations.
Notably, the read histogram plot reveals "gaps" between bins, likely caused by the skip list algorithm utilized under the hood.

This configuration has not affected the CPU/RAM/Disk consumption, likely due to manual locking. While initial data loading was fast (100,000 nodes and relationships in less than two minutes), the absence of ACID guarantees forced us to make a manual safety lock mechanism. This, in turn, severely reduced database throughput.
Test 8: Memgraph with on-disk transactional method

This configuration was run using the on-disk transactional mode, which turned out to be quite fast on write operations (both in p90 latency and total write time), and fast on reads, matching our usage scenario.

The disk usage graph looks much smoother, likely due to some scheduling of “disk flush” operations which makes disk load more predictable. CPU and RAM usage patterns have not changed since previous test.
Nebula Graph
Test 9: Nebula Graph with default configuration

The performance of write requests is better than for Memgraph, the read queries are fast. The write graph resembles the situation with Memgraph configuration 1, where periodic spikes were observed. Overall CPU load and disk usage are within acceptable limits.

In this configuration, the RAFT consensus algorithm was disabled because we did not need to control the synchronization of writes between different servers, and there was only one instance of each service running. This resulted in slightly lower query response time.
Test 10: Nebula Graph without optimizations

When we’ve disabled optimizations, the results showed more spikes in disk write load. However, CPU usage and RAM consumption remained unchanged. Write performance was a bit higher,, but read performance slightly dropped.

Test summary
| Test | p90 Write [ms] | p90 Read [ms] |
CPU [%] |
Disk writes [KiB\Sec]] |
RAM [MiB] |
Time [min] |
Neo4j
| Neo4j Test 1 | 15.50 | 9.70 | 81.19 | -61 196.7 | 113 331.5 |
1 |
| Neo4j Test 2 | 15.81 | 10.63 | 80.76 | -62 509.81 | 112 955.27 | 1 |
| Neo4j Test 3 | 14.91 | 9.88 | 75.12 | -60 747.03 | 115 442.49 | 1 |
| Neo4j Test 4 | 15.17 | 9.79 | 77.67 | -61 189.48 | 112 944.91 | 1 |
| Neo4j Test 5 | 14.74 | 9.83 | 80.62 | -60 634.93 | 114 265.35 | 1 |
Memgraph
| Memgraph Test 6 | 70 | 1.33 | 38.59 | -6 215.04 | 120 516.58 | 14 |
| Memgraph Test 7 | 75 | 1.43 | 37.83 | -5 857.42 | 1 205 40.1 | 12 |
| Memgraph Test 8 | 70.41 | 1.41 | 38.02 | -4 017.37 | 120 491.02 | 14 |
Nebula Graph
| Nebula Test 9 | 42.72 | 1.31 | 29.27 | -23 288.79 | 119 662.88 | 1 |
| Nebula Test 10 | 42.69 | 1.34 | 28.85 | -23 532.71 | 119 461.79 | 1 |
Based on the conducted tests, we can draw the following conclusions:
1. Neo4j, using its default settings, showed the lowest read performance. However, write operations are characterized by high jitter, which can pose challenges for systems under heavy load. Variations in garbage collector configurations (G1GC, ZGC, ParallelGC) have a negligible effect on overall performance and resource utilization..
2. Memgraph excels in read operations, though its overall performance lower than Neo4j and Nebula, but higher in reads. Its in-memory architecture, while a key design consideration, necessitates careful handling of API-level errors and responses. Furthermore, its high-performance analytical engine sacrifices ACID compliance, limiting its applicability to specific tasks.
Nebula Graph shows well-rounded performance, delivering good metrics for both read and write operations while consuming less memory. It's possible to deploy it without RAFT, but this configuration compromises its fault tolerance. Additionally, Nebula Graph utilizes its own query language, nGQL, which may require an additional time investment for teams to learn.
When choosing a graph database, it is important to consider not only performance but also the requirements for ACID compliance, scalability, and the specific features of your use case. For applications requiring maximum read performance and in-memory data handling, Memgraph is a strong contender. For distributed systems with high scalability demands, Nebula Graph offers interesting capabilities. Neo4j, as the most mature solution, remains a reliable choice for many scenarios.
In our project, we ultimately chose Nebula for a workload with intensive read|write operations, where speed and efficiency were critically important, and this solution fully met our expectations.
Later, we will paste the story of how we fixed the 7-year-old bug in one of the candidates, if I have time.
Practical application experience: Recommendation system
During the creation of our in-house recommender system, we constructed a personalization engine utilizing a graph database (Nebula) because of overall performance. In this model, users, items (like products or content), and their features were represented as nodes, while the connections between them, signifying interactions (e.g., views, purchases, ratings) and relationships (e.g., item similarity, user preferences), were defined by edges. This methodology enabled us to effectively generate highly relevant suggestions by analyzing these connections. As an illustration, we identified paths linking users to new items through shared interests or the behavior of similar users, and streamlined the generation of tailored recommendation feeds through graph-based traversal techniques.
Leveraging this prior experience, we’ve constructed a Personalized Customer Engagement project for a client. We structured their data as a graph, with nodes for customers, products, interaction events, and content pieces, and edges to map out Browse history, purchase patterns, and the links between these data points. We then implemented recommender-inspired mechanisms, such as real-time preference updates based on interaction triggers (for instance, adjusting a user's interest profile after they engage with specific content) and the visual representation of customer journey paths and influence networks. This empowered the client to rapidly discover opportunities for personalized offers and to automate various operations, such as delivering contextually relevant content in real-time.
Consequently, our internal recommender system served as an initial proving ground for methods that ultimately equipped the client with deeper insights into customer preferences and behavior, thereby reducing the need for manual curation of recommendations or less effective generic targeting. The central insight is that graph technologies demonstrate significant value not just for building sophisticated recommendation engines, but in any situation where the intricate relationships between different entities are the core challenge for understanding behavior and delivering personalization.
---
The Article was reviewed by Hleb Skuratau, CEO and CTO at T4itech.


